How Website Structures impact the Success of Data Scraping Projects
In today’s data-driven world, the ability to scrape and analyze details from websites has become an invaluable skill for businesses, researchers, and tech enthusiasts alike.But have you ever paused to consider how the very structure of a website can make or break your scraping project? If you’ve ever wrestled with a stubborn webpage that just wouldn’t give up its data, you know what I mean.
Website structures play a pivotal role in the success of your data scraping endeavors, influencing everything from the amount of information you can extract to the efficiency of your scraping tools. In this article, we’re going to explore how different website architectures—like HTML layout, the use of JavaScript, and content management systems—can affect your scraping success. Whether you’re a seasoned developer or a curious beginner,understanding these nuances will not only save you time but also elevate your data scraping projects to new heights. So, let’s dive in and uncover the secrets that can turn your scraping challenges into triumphs!
understanding Website Structures and Their Importance for Data Scraping Success
Understanding the structure of a website is crucial for anyone looking to embark on a data scraping project. Websites are built with a specific architecture that dictates how information is organized and presented. A solid grasp of this structure not only enhances the efficiency of scraping but also ensures that the data extracted is reliable and accurate.
At the core of any website is its HTML structure. This includes elements such as headings, paragraphs, links, and lists that define how data is displayed. By understanding these elements, data scrapers can effectively locate the information they need. For instance, information contained within
- Efficiency: Knowing where to look means less time spent sifting through irrelevant data.
- Accuracy: A well-planned scraping strategy considers the hierarchy of information, reducing the chances of missing critical data points.
- Adaptability: A deep understanding of the layout makes it easier to adjust scraping methods if the website undergoes changes.
Another key aspect is the use of CSS classes and IDs. Many websites employ classes and IDs to style their content, and these can also serve as indicators for scraping. Such as, if a product price consistently appears within a specific class, targeting that class simplifies the scraping process.
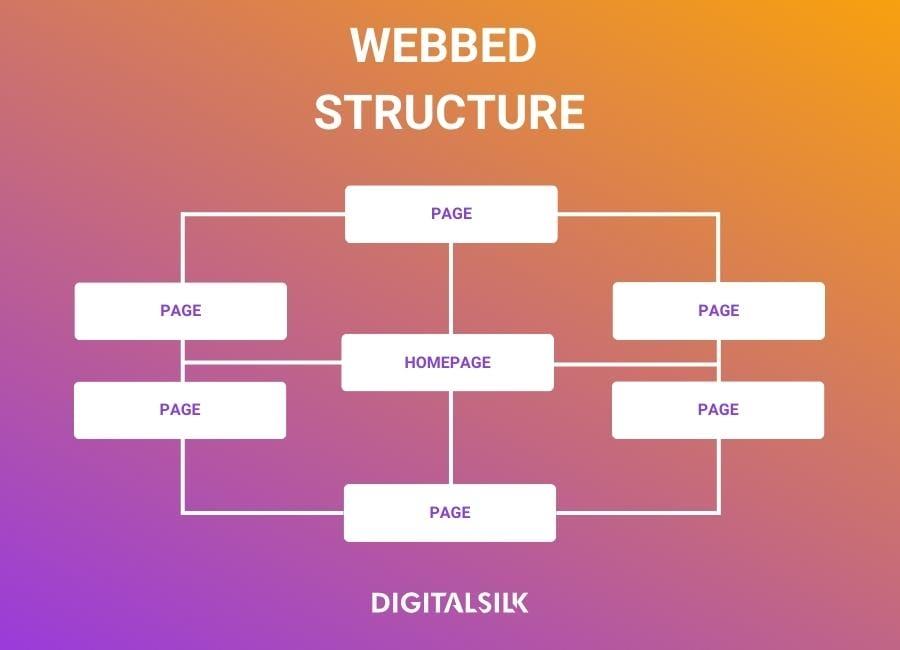
Additionally, the link structure plays a vital role in how data can be collected. Websites frequently enough use pagination,where information is spread across multiple pages. Understanding the site’s navigation can definitely help scrapers to follow links systematically and gather data without missing any vital information. Here’s a simple representation of common link behaviors:
| Link Type | Description |
|---|---|
| static Links | Direct links to content that remains consistent. |
| dynamic Links | Links that change based on user interaction or parameters. |
| Pagination Links | Links that lead to additional pages of content (e.g., “next” buttons). |
Ultimately,the importance of mastering website structures cannot be overstated. By harnessing the power of structured knowledge, data scraping efforts can yield more successful and meaningful results. Whether you are a seasoned developer or a novice, investing time in understanding the website’s architecture will pay off in the long run.
The Anatomy of a Well-Structured Website and Its Role in Data Accessibility
When considering the design of a website, its structure plays a pivotal role, especially in the context of data scraping projects. A well-structured website not only enhances user experience but also facilitates easier extraction of data. Think of it as the architectural blueprint of a building; without a solid foundation and clear layout, navigating the site—and retrieving valuable data—becomes a challenge.
Key elements that contribute to effective website structure include:
- Intuitive Navigation: menus and links should be organized logically,allowing users (and scrapers) to find information with minimal effort.
- Consistent URL Structure: Clear, descriptive URLs make it easier to identify the content type and hierarchy, aiding data extraction tools in targeting specific pages.
- Semantic HTML: Utilizing proper HTML tags not only boosts SEO but also helps scrapers understand the context and relevance of data within the page.
Another vital aspect is the utilization of metadata. By providing structured data through schema markup, websites can offer rich snippets that enhance visibility in search results and simplify the scraping process. Search engines and scrapers alike can interpret these signals to access content more effectively, leading to more accurate data retrieval.
However, it’s essential to consider the role of responsive design. A website that adapts seamlessly across devices ensures that data scraping tools can access the same information irrespective of the viewport. Poorly structured mobile versions may hinder scraping efforts, leading to incomplete or skewed data.
the anatomy of a well-structured website encapsulates various components that significantly impact data accessibility. By prioritizing intuitive navigation, consistent URLs, semantic HTML, metadata, and responsive design, web developers can lay down a path for successful data scraping projects. The benefits are twofold: not only does it enhance user experience, but it also opens the door for accurate, efficient data extraction.

Navigating Through HTML: Key Elements that Facilitate Effective Data Scraping
When embarking on a data scraping project, understanding the underlying structure of HTML is crucial. The elements that compose a webpage not only determine its aesthetic appeal but also influence how effectively you can extract data. By leveraging key HTML elements, scrapers can navigate through web documents with precision and ease, ensuring their projects yield successful results.
one of the foundational aspects of HTML that aids data scraping is the use of tags. In most cases, the
Another critical element is the tag, which represents hyperlinks. This tag not only allows scrapers to find navigational pathways but also helps in pulling related data from multiple pages, creating a more comprehensive dataset. By examining the structure of links within a webpage, developers can build efficient scraping algorithms that traverse through interconnected content seamlessly.
| HTML Element | Purpose in Scraping | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Defines sections of content for isolation | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Facilitates navigation and data retrieval | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Additionally, the use of the
|